WordPressの代わりとなるMarkdownエディタ&Codex内蔵のWebサイト構築アプリMdHE(Markdown HTML Editor)
WordPressの代わりに、Markdownで記事を管理して、静的HTMLとして出力できるWebサイト構築アプリMdHEを使っています。本文は.mdファイルで管理できるため、LLMによる編集、翻訳、要約と相性がよく、Git管理やバックアップも簡単です。公開ページに近い見た目で編集でき、Codex連携やllms.txt出力、画像ドロップ、YouTube差し込みなどにも対応しています。
| テキスト文字数21132 43.8kb | LLMへテキスト貼り付けできます。
WordPressの代わりにMdHEを作った
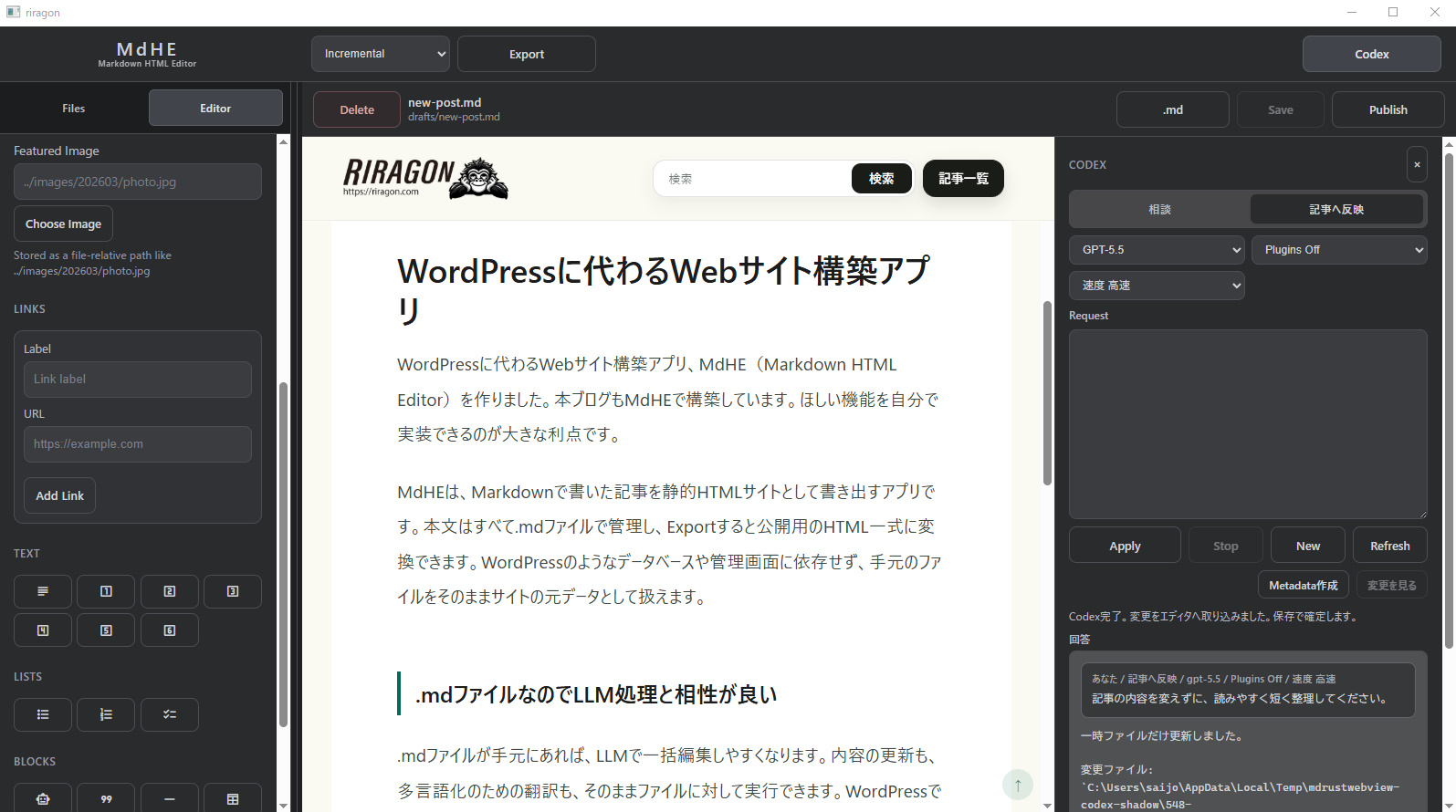
WordPressに代わるWebサイト構築アプリ、MdHE(Markdown HTML Editor)ですが、本ブログもMdHEで構築しています。ほしい機能を自分で実装できるのも大きな利点です。MdHEは、Markdownで書いた記事を静的HTMLサイトとして書き出すアプリです。本文はすべて.mdファイルで管理し、Exportすると公開用のHTML一式に変換できます。WordPressのようなデータベースや管理画面に依存せず、手元のファイルをそのままサイトの元データとして扱えます。
.mdファイルなのでLLM処理と相性が良い
.mdファイルが手元にあれば、LLMで一括編集しやすくなります。内容の更新も、多言語化のための翻訳も、そのままファイルに対して実行できます。WordPressでも記事をダウンロードすれば近いことはできますが、AI時代のデータ管理としてこのほうが最適です。

公開ページそのままのデザインで編集できる
昔から欲しかったのは、公開されるサイトデザインを見ながら記事を編集できる機能です。MdHEでは、Markdownで管理しながら、公開ページと同じ見た目で本文を整えられます。WordPressの入力画面ではなく、HTMLとして表示される状態を見ながら編集できます。
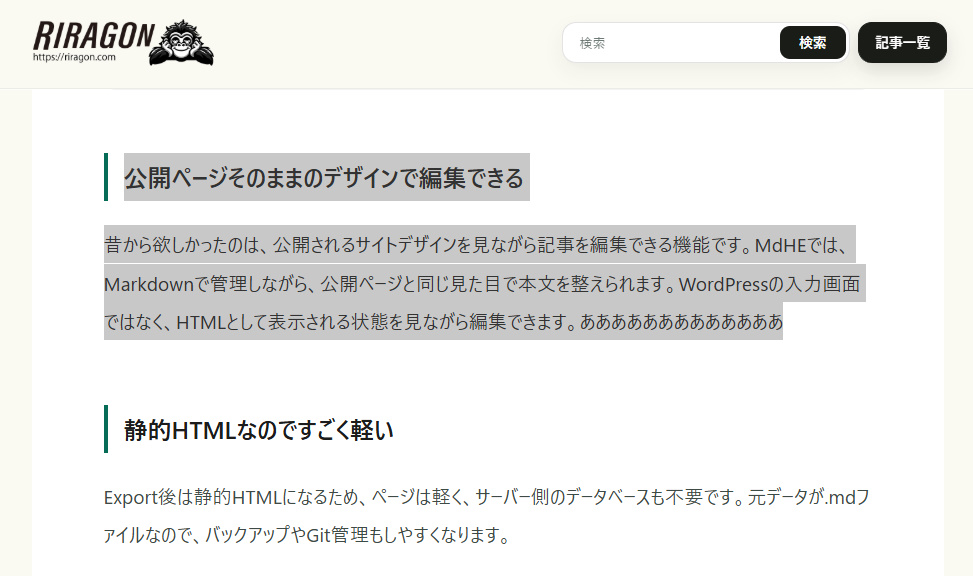
静的HTMLなので軽い
Export後は静的HTMLになるため、ページは軽く、サーバー側のデータベースも不要です。元データが.mdファイルなので、バックアップやGit管理もしやすくなります。
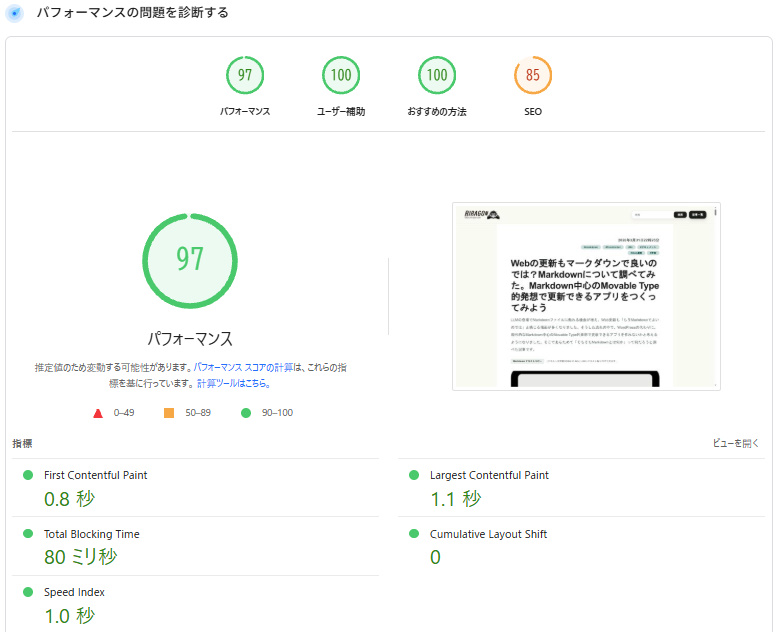
アプリにCodexも組み込み
MdHEアプリ内にはCodexも組み込んでいます。記事を書きながら、見出し案、言い換え、要約、構成の相談を同時に進められます。AIに丸投げするのではなく、書き手が本文を見ながら共同編集できる形です。同時に編集しても上書きしない仕組みも入っています。
AI向けには llms.txt も出力します。サイトの内容をAIが読み取りやすい形でまとめられるため、これからのWebサイト運用にも向いています。ほかにも、必要に応じてさまざまな機能を実装しました。画像のドロップやYouTube動画の差し込みなどにも対応しています。
MdHEの弱点と今後の課題
もちろん弱点もあります。静的HTMLの書き出しなので、記事を追加したら毎回FTPでサイトをアップロードする必要があります。今はWinSCPを使っています。FTP機能はいずれMdHEにも追加したいですが、WinSCPが優秀なのでしばらくはこのままでも困っていません。
サーバーで動作するWordPressは、ある意味でクラウド型のCMSです。記事を書いて公開すれば、すぐサイトに反映されます。ログインすればどこからでも記事を書けます。MdHEはローカル管理なので、編集用PCから書き出す手間があります。
サーバーでMdHEを動かしてブラウザ経由で操作する形も考えられます。GitにMarkdownファイルを置いて、同じような更新フローにする方法もありそうです。ただ、そこまでいくとWordPressや既存CMSとの違いが薄くなるので、今はローカルで軽く管理できる方向を優先しています。
ほかにも、WordPressのようなテーマやプラグインの資産はありません。コメント、検索、フォームのような動的な機能も、必要なら外部サービスを使うか自分で実装する必要があります。自由に作れる反面、便利な仕組みを自分で用意する場面は増えます。
MdHEを作るときに類似の仕組みアストロとか、Markdownファイルについて調べた内容が以下です。LLMのながーいスロップです。ほんと長いですからね。
更新履歴
- 2026-05-24-01-Codex変更を戻す
更新情報・連絡先は X(Twitter) @riragoncom へ。
詳しい説明(クリック)Markdownがどう進化して、今なぜ重要で、実務でどう使うか AIの登場でMarkdownファイルに触れる機会が増え、Web更新もMarkdownで足りるのではと感じる場面が増えました。そうした流れの中で、WordPressやMovable Typeの代わりに、現代的なMarkdown中心のMovable Type的発想で更新できる仕組みを考えています。本稿は、その前提としてMarkdownの起源・仕様・周辺フォーマット・AI時代の扱いやすさ・実務での構成の一例を順に整理す...
Markdownがどう進化して、今なぜ重要で、実務でどう使うか
AIの登場でMarkdownファイルに触れる機会が増え、Web更新もMarkdownで足りるのではと感じる場面が増えました。そうした流れの中で、WordPressやMovable Typeの代わりに、現代的なMarkdown中心のMovable Type的発想で更新できる仕組みを考えています。本稿は、その前提としてMarkdownの起源・仕様・周辺フォーマット・AI時代の扱いやすさ・実務での構成の一例を順に整理するメモです。
Markdownは2004年に、読みやすいプレーンテキストを構造的に妥当なHTMLへ変換する考え方で登場しました。その後は実装差が広がりましたが、書き方と変換結果をそろえる共通ルールのCommonMarkと、GitHub上で表やチェックリストなどを扱う拡張ルールのGFMによって整理が進みました。
さらに実務では、Markdown本文にUI部品やJavaScript記述を混ぜられるMDX、本文先頭のメタ情報を機械的に読めるfrontmatter、そして項目ルールを先に定義して入力ミスを自動検知する型つきコンテンツ層へと発展しています。つまりMarkdownは、単なる記法から「検証できるコンテンツ基盤」へ進化してきたといえます。
2020年代後半のMarkdown運用では、HTMLの書き出しだけでなく、frontmatterとschemaを組み合わせて、項目・型・入力ルールを検証できる情報として扱う設計が増えています。あわせて、人間向けHTML、LLM向けMarkdown、検索索引、構造化データJSON-LDへ展開する運用も広がっています。
Astroは、その流れを実装しやすくする代表例です。Content Collectionsでfrontmatterを整理し、Zodで検証し、Content Layer APIでローカルとリモートのコンテンツを同じ形で読み込める流れが示されています。
AI時代にMarkdownが再評価される理由は、LLM入力としての境界が見出し・段落・コードフェンスなどで取りやすいこと、HTML→MarkdownやPDF→Markdownなど変換・抽出パイプラインの共通中間表現になりやすいこと、Git差分・レビューにプレーンテキストとして強いことが、ベンダーのプロンプト指針や実運用に噛み合っているためです。具体例として、OpenAIやAnthropicのガイド、Next.jsのエージェント向けローカルMarkdown docs配布が挙げられます。
Markdown中心の更新アプリを設計するとき、入力形式や方言差がそのままバグや表示ズレになります。次の節では、なぜCommonMarkやGFM、RFCの話がその前提整理に効くのかを、歴史と仕様の流れで押さえます。
起源と仕様の進化
Markdownの原点 ― 2004年
Markdownは、John Gruber により「Web writers 向けの text-to-HTML conversion tool」として2004年に提案され、可読性の高いプレーンテキストから構造的に妥当なHTMLを生成することを設計思想としていると述べられています。
ここで重要なのは、原典のMarkdownが万能な文書形式としてではなく、Webライター向けのシンプルな text-to-HTML 変換道具として出発した点です。少なくとも出発点の思想は、「何でもMarkdownで表現する」ことではなく、読みやすいプレーンテキストでWeb向け文章を書くことにありました。
この設計は、のちの「静的サイトジェネレーター」「ドキュメントサイト」「AI入力用中間表現」にもそのまま転用可能で、後述の「単一ソース→多出力」アーキテクチャと整合します。
ローカルルールの増加と、仕様化による収束:CommonMark/GFM
Markdownは「非形式的な記述+参照実装」に依存していたため実装が分岐しやすく、これを解決する目的でCommonMarkは「曖昧さのない仕様」+「実装を検証する包括的テスト」を提案しています。
CommonMark Specは版管理されており、少なくとも 0.13・2014-12-10付から 0.31.2・2024-01-28付まで、仕様とテストの改良が継続していることが公式ページに明示されています。
一方、GitHub上で広く使われるGFM=GitHub Flavored Markdownは、CommonMarkをベースにした「formal specification」として定義され、2019-04-06版の0.29-gfmが明記されています。
この流れは、Markdownをできるだけ簡潔に保ちたい原典の思想と、表・タスクリスト・脚注のような機能を求める実務の要求がぶつかった結果とも読めます。CommonMarkやGFMは、原典の単純さをそのまま守るというより、広がってしまった実装差を現実的にそろえる試みでした。
「ファイル形式としてのMarkdown」を支えるIETF/IANA ― 2016年
2016年、RFC 7763により text/markdown メディアタイプが登録され、MarkdownはHTMLなどへ変換可能なプレーンテキスト形式として定義されました。 RFC 7763では、IANAに Markdown Variants レジストリ が設けられ、variant識別子によってMarkdownのローカルルールを区別する仕組みが定義されています。
このレジストリは2015-10-22に作成され、Original、GFM、CommonMark、pandoc、MultiMarkdownなどが登録されています。 またRFC 7764は、Markdownの設計哲学、安定化戦略、および登録例についての補足ガイダンスを提供しています。
仕様進化の要点まとめ ― Mermaidタイムライン
上記の各節は、Markdown、CommonMark、GFM、RFC、IANA、MDX、Stack Exchange、Astro、llms.txt、Mistral OCR、ReaderLM-v2、Next.jsなどの原典や公式情報に基づいて整理しています。細部や最新情報を確認したい場合は、参考リンク先の原文を参照してください。
近年の「Markdown周辺フォーマット」発展
正本をMarkdownに置く構成では、本文だけでなくメタデータや型検証、編集UIまで含めて設計します。次の各節は、その部品候補として実務でよく出てくる周辺フォーマットを並べたものです。
言い換えると、ここから先で扱うMDX、frontmatter、Content Layer、Git-backed CMSは、原典のMarkdownそのものというより、Markdownを正本に据える実務の中で積み重なってきた拡張層です。
MDX:Markdown + JSX + import/export ― 2018年〜
MDXは、文章の中に動く部品を入れられる書き方です。ふつうの説明文に、注意ボックスやタブを同じページで置けます。MDXは、Markdown本文の中にJSXやJavaScript式、ESMの
import/exportを含められる「authorable format」として説明されています。この性質は、ドキュメントサイトが「文章」と「UIコンポーネント、アラートやタブ・グラフなど」を同一ファイルで共存させたい場合に強く効きます。DocusaurusはMDXのビルトインサポートを明記し、MarkdownファイルをMDXコンパイラでReactコンポーネントへ変換して「インタラクティブなドキュメント」を可能にすると説明しています。
Next.jsも、MDXを「markdownのスーパーセット」として扱い、ローカル/リモートMDXをサーバー側で取得してHTMLへ変換できる、と公式に述べています。
frontmatter:本文の上に「メタデータ」を載せる慣習 ― Jekyll起源と拡散
frontmatterは、記事のいちばん上に置く「説明カード」です。タイトルや日付、タグを先に書いておくと、機械が整理しやすくなります。
YAML frontmatterは、Jekyllで普及した「Markdownファイル先頭に置くキー・バリューのメタデータブロック」として、GitHub Docsの公式執筆規約でも説明されています。
静的サイトの代表格であるHugoは、frontmatterを「コンテンツの説明・拡張・関係付け・公開構造の制御・テンプレ選択に使うメタデータ」と定義し、YAML/TOML/JSONのいずれでも書けるとしています。
ここで重要なのは、frontmatterが「人間のための装飾」ではなく、ビルド・検索・並べ替え・関連付け・権限制御など、機械処理のためのセマンティクス的な意味を担う点です。
Content Collections / Content Layer:Markdownを「型付き・クエリ可能」にする ― Astro
Markdownや記事データを「決めた形」にそろえ、プログラムから探したり並べたりしやすくする仕組みです。ルールに合わない項目があれば、だいたいビルドのときにエラーになり、公開前に気づけます。Content Collectionsでは、公式の説明どおり、Zodなどのスキーマでfrontmatterやエントリを検証し、必要な項目だけを揃えたデータとして扱えます。
そのうえで、2024年の公式ブログでは、従来の「スキーマ・frontmatterの検証・TypeScript向けの検索API」に加え、ローカルだけでなくリモートのソースも同じ考え方で扱う「Content Layer」へ広げる、という方向が示されています。
Content Loader(Content Layerの入り口)のドキュメントでは、load()のなかで取得(fetch)→スキーマで読み取り・検証→データストアを更新までをまとめて担当すること、Zodのスキーマを渡して検証に使えることも書かれています。
記事用Markdownをルールどおりのデータにそろえ、ビルドの段階でミスに気づきながら、サイト側から一覧・参照・並べ替えしやすくする仕組みです。Content Layerは、そのやり方をローカルのファイルだけでなく、リモートから取ってきたコンテンツにも広げる、というイメージです。
Git-backed CMS:Markdownを「GitのままUI編集」する ― TinaCMS
昔のブログCMSのように記事を書いて公開する体験に近い一方で、本文はMarkdownファイルのままGitに残す、という発想です。Movable Type的な「下書き・公開・テンプレ」との対比で言えば、記事の正本をリポジトリ上のMarkdownに置き、ビルドやデプロイでHTMLへ出す、という現代的な形に近い例として読めます。
文章ファイルをそのまま残したまま、見た目で編集できる仕組みです。編集した内容はGitに保存されるので、だれが直したかあとで追えます。特別なデータベースに閉じこめられないので、引っこしもやりやすいです。
TinaCMSは、自身を「オープンソースのGit-backedヘッドレスCMS」と説明し、コンテンツをMarkdown/MDX/JSONファイルとしてGitで保持し、専用DBにロックインしないと明言しています。
さらに、TinaCMSはGraphQL APIによりMarkdownコンテンツをクエリ可能にし、参照やライブプレビュー等をREADMEで示しています。
post.author.firstNameのようなフィールド参照が例として挙げられています。Astro公式ドキュメントにも、TinaCMSを「Git-backed headless CMS」として統合手順が掲載されており、静的サイト系フレームワークの運用文脈で「Markdown+Git+編集UI」が一般化していることが読み取れます。要するに「CMSの使いやすさ」と「Git運用の透明性」を両取りする仕組みです。
AI時代にMarkdownが強い理由
プロンプトやドキュメントでMarkdownを扱う機会が増えたからこそ、なぜ境界が読みやすいのかを押さえておくと、自分のエディタやプレビュー設計にも戻しやすいです。
ただし、これはMarkdownが万能という意味ではありません。複雑な構造や厳密なデータ交換では、XML、JSON、SQL、専用CMSの方が向く場面もあります。ここで見たいのは、そうした形式がある中でも、Markdownがどの役割で強いのかという点です。
LLMが「境界」を読む:Markdownはセクション分割の最小単位を備える
OpenAIはプロンプトエンジニアリングのガイドで、MarkdownとXMLタグを組み合わせて「論理的境界」を明確にできると説明しています。またOpenAIのGPT-4.1向けガイドは、区切りdelimitersの推奨として Markdown→XML→JSON の順で述べ、Markdownでは見出し階層、コードはバッククォート/コードフェンス、リストの活用を推奨しています。
これは「モデルがMarkdownを特別視している」というより、見出し・段落・箇条書き・コードブロックという境界が、LLMにとっても人間にとっても解釈しやすい、という実務上の帰結として理解できます。
Anthropic側も、複雑なプロンプトはXMLタグでコンテンツ種別をinstructions/context/inputなどに分けると誤解が減ると述べています。Markdown単体ではなく、必要ならタグも併用する設計が現場で増える背景になります。
つまり実務では、まずMarkdownでわかりやすく構造化し、必要なところだけXML/JSONで厳密化するのが有効という話です。
トークナイゼーション観点:空白の有無より「再現可能な構造と繰り返しパターン」
トークナイザは、文章をAIが扱いやすい小さな単位に分ける仕組みです。日本語はスペースで単語を区切らないことが多いですが、最近の方式は空白の有無に強く依存しません。SentencePieceのように、単語分割前の生文(raw sentences)から直接学習できるものもあります。
BPE(Byte Pair Encoding)は、よく一緒に出る文字の並びを少しずつ1つのかたまりにまとめる方式です。こうしてできた「サブワード」を使うことで、語彙サイズと文の長さのバランスを取りながら効率よく処理できます。
この点でMarkdownは有利になりやすいです。
#、コードフェンス、-などの記号が繰り返し現れ、空行で段落が区切られ、見出しで階層も明示されるため、トークン列の中に構造の手がかりが入りやすいからです。要するに、Markdownは日本語でも構造の目印が多く、AIが解釈しやすくなりやすいということです。HTML/PDFなど「ノイズの多い入力」からの共通中間表現としてのMarkdown
AI時代の大きな変化は、Markdownの役割が広がったことです。Markdownは、人が直接書く形式であるだけでなく、HTMLやPDFから内容を抜き出したあとに整える「共通の中間形式」としても使われるようになっています。
たとえばMistral OCRは、PDFからテキストや画像を抽出して、markdown fileとして出力する例を公式に示しています。ReaderLM-v2の2025年研究でも、ノイズの多いHTMLをcleanなMarkdownやJSONに変換することが、LLMのgroundingに有効だと説明されています。
つまり、WebやPDFをいったんMarkdownに変換してからRAG・検索・QAに回す流れが、前処理の定番になりつつあるということです。
Git差分・レビュー・履歴管理:プレーンテキスト資産としての強さ
Markdownはプレーンテキストであり、Gitの差分表示やレビューに向く、というのは経験則として語られがちですが、Git側のドキュメントは「バイナリファイルは差分が出にくい/diffのためにテキスト化フィルタを用意する」という前提を説明しています。つまり、テキストであること自体が差分・マージ可能性を上げるという構造です。
この性質は、ドキュメントをWordやPDFの「成果物だけ」で残す運用と対比すると、AI時代により重要になります。なぜなら、LLMへの入力だけでなく、人間のレビュー・履歴・再利用や再ビルドが同時に必要になるケースが増えたためです。
具体例:
2020–2026の採用事例:一部紹介(代表5例)
以下は、公式・一次情報を中心にした採用事例の一部紹介です。全件一覧ではなく、代表的な5例に絞って掲載します。Markdownは一部ではなく、Q&A、公式ドキュメント、AIパイプライン、フレームワーク運用まで広く使われていることが分かります。
/llms.txtを追加し、背景・ガイダンス・詳細Markdownへのリンクを提供、さらにページのクリーンな.md版生成も提案AGENTS.mdをcreate-next-appに同梱し、node_modules内に「plain Markdown」のバージョン一致docsをバンドルする、と公式ブログで説明採用例のうち、日本語一次情報として、MDNの日本語執筆ガイドのGFMベース、Stack Overflow日本語メタのCommonMark切替告知などが確認できます。Markdownが単なる記法ではなく、人間向け表示とAI向け処理を両立するものとして定着してきているわけです。
事例はあくまで代表例であり、自サイトではスタックや規模で最適解は変わります。次の章では、Markdownを正本に置く前提での構成の一例を書きます。自分が考えているMarkdown中心の更新フローが、どの部品に相当するかの当たりにも使えます。
実務での構成を考える
前節の採用事例を見ると、Markdownは「書き方」だけでなく、公開・検索・AI利用まで含む運用基盤として使われていることがわかります。実務構成にはCMS中心、DB中心、HTML中心などさまざまな形があります。ここではその中の一例として、Markdownファイルを正本にして用途別に出力を分ける考え方を見ていきます。
Movable Type的にいえば、記事本文とメタを一度正本にまとめ、テンプレートやビルドで人間向けHTMLや付帯ファイルへ出し分けるイメージに近いです。GitとMarkdownを組み合わせると、差分とレビューも取りやすくなります。
「単一ソースの.md」から多出力を考える
Markdownを正本とする運用では、single source of truthを1つにし、そこから用途別に出力を分ける形が管理しやすくなりやすいです。
index.htmlとindex.mdを別原稿として二重管理すると、更新ずれや修正漏れが起きやすくなります。以下では、そのズレを減らすための一つの構成例を示します。/llms.txt提案も、サイトにLLMフレンドリーな入口を置き、必要なら各ページのクリーンなMarkdown版をURLに.md付与で持つことを提案しています。つまり、正本から用途別のMarkdownを派生させる発想そのものは、仕様提案側にも見られます。一例としての生成ターゲット整理:index.html / index.md / llms.txt / search-index / JSON-LD
index.html:人間向けの表示。Markdownの原典思想であるtext→HTMLに直結します。index.md(公開ディレクトリ内):ローカル運用上の「派生物」で、規格名ではありません。ナビ・装飾を落とし、見出し構造と要点を保ってLLMが読みやすい「クリーン本文」にする用途です。根拠としては、HTML→MarkdownやPDF→MarkdownがLLM向け前処理として使われる流れ、ReaderLM-v2やMistral OCRに整合します。llms.txt:ルートに置く「案内板」。仕様提案として、背景・ガイダンス・詳細Markdownへのリンクを提供し、コンテキスト制約やHTMLノイズ問題を緩和する狙いが明記されています。search-index.jsonまたは Pagefindバンドル:全文検索用の索引。Pagefindは「静的ジェネレータの後に実行し、生成済みサイトに静的検索バンドルを出力する。索引は生成済みサイトから自動生成される」と説明しています。この例で挙げているもののうち、規格として策定されているのはJSON-LD=W3C Recommendationで、llms.txtは提案仕様、公開用の
index.mdはローカル規約です。フォルダ構成例:ページ単位とサイト共通を分離
この一例では、
test240205content/にすべてを詰め込むより、ページ単位の成果物とサイト全体の成果物を分けるほうが管理しやすいと考えます。llms.txtはルート配置を想定しています。Pagefindも「ビルド後にサイト全体を索引化する」フローです。例:
一方、外部検索エンジン・クローラはリンク構造やサイトマップ等に依存することが多く、発見性は別途設計が必要になります。本稿では主題外のため深入りせず、llms.txtやsitemap等の一般論に留めます。llms.txtは「LLMが読む入口」として別レイヤーを用意する発想です。
形式比較とLLM可読性
ここでは数値順の絶対順位ではなく、LLM入力としての扱いやすさを用途別に並べた目安です。用途が変われば順位も入れ替わります。
形式の役割別整理:Markdown / MDX / frontmatter / JSON-LD / 検索索引 / SQL
形式がいろいろ出てきたので、役割ごとにざっと整理します。どれが本文向きで、どれがメタデータ向きか、用途の違いがひと目でわかるようにまとめました。
補足として、Astroは将来的にコンテンツ層の内部ストレージとしてSQLite=LibSQLを探索し、より強力なクエリを提供できる可能性に言及しています。これは「SQLがMarkdownの代替」というより、Markdownを起点に「内部表現としてのDB」を使う方向です。
LLM入力としての「読みやすさ」の目安として、次のような並びで整理してもよい、という一例です。用途によって逆転は普通にあります。
推奨frontmatter項目とサンプルファイル
ここまでで、本文形式と補助形式の役割、そしてLLM入力としての扱いやすさを整理してきました。次は、Markdownを正本にする更新アプリやサイトを組むときの、実装イメージの一例として、運用時にぶれにくいfrontmatter項目と最小のサンプルを示します。採用する項目は規模と要件で変えて構いません。
推奨frontmatter ― 汎用
frontmatterの設計にはいろいろな形があり、用途によって必要な項目は変わります。ここでは、その中でもサイト生成・検索・AI利用を一緒に考えるときに使いやすい、汎用的な一例を挙げます。
id… 不変IDtitledescription… 短い要約slug… URL制御status…draft/published/archivedなどcreated_at/updated_attags… 配列category… 単一分類canonical_url… 正規URLsource_url… 外部ソースがある場合language… 例javisibility…public/private/internalrelated… 関連IDの配列GitHub DocsはYAML frontmatterを「バージョニング、メタデータ、レイアウト制御」に使い、さらにfrontmatterを検証するschemaが存在すると明記しています。またMicrosoftの.NET docsテンプレは、
title/description/author/ms.date等のメタブロックを要求しています。つまりfrontmatterの中身は用途ごとに違っても、必要な管理情報を先頭でそろえて扱う考え方自体は広く共有されています。つまり簡単にいうと、frontmatterは飾りではなく、公開や運用に必要な管理情報です。項目の組み方は使い方しだいですが、主要なドキュメント基盤では「必要な項目を決めて入れ、ルール違反は検証で防ぐ」という考え方が広く使われています。
サンプル:正本
index.mdここまでで、frontmatter項目の一例を整理しました。次に、実際にどのような形で書くかをイメージしやすいように、正本となる
index.mdの最小サンプルを示します。サンプル:派生
index.md― ローカル運用例LLM向けに、ナビ・余計なUI文言を落として、必要なら「メタ要約」を先頭に置く例です。提案であり標準ではありません。
サンプル:
/llms.txt― 提案仕様llms.txt提案は、背景・ガイダンス・詳細Markdownリンクを決まった順序で置くこと、そして「ページのクリーンMarkdown版、URL+.md」の併設も提案しています。
サンプル:JSON-LD ― HTMLに埋め込む
JSON-LDはW3C勧告で、JSONベースでLinked Dataを表現し、既存JSONへの統合のしやすさを狙うと説明されています。
検索インデックス:SQLではなく「索引データ」
Pagefindは、静的ジェネレータが吐いたHTMLを後段で解析して、検索バンドル=索引を生成する、と説明しています。つまり索引は検索のためのデータ構造で、SQLのような汎用クエリ言語によるデータベースそのものとは役割が異なります。
ただし、Astroが「内部ストレージとしてSQLiteを使う可能性」に言及しているように、コンテンツ管理レイヤの内部表現としてSQL/SQLiteが出てくることはあり得ます。これは検索インデックスとは別の話です。
以上が、Markdown中心のMovable Type的更新を考えるうえでの前提整理です。入力形式の歴史と標準、周辺フォーマット、AI時代の扱いやすさ、採用の広がり、そして正本Markdownからの多出力の一例までを一通りなぞりました。
今回調べてみて、いま作ろうとしているアプリは、単にMarkdownを編集する道具ではなく、Markdownを正本にしてWeb公開やAI利用へつなぐための基盤として考えるのがよさそうだとわかりました。何でもMarkdownに寄せるのではなく、Markdownが向く部分を中心に据えつつ、必要なところだけ別の仕組みで補う。そうした現代的なMarkdown中心のMovable Type的発想として整理するのが自然です。
Astroと類似アプリ
その発想を実装するスタックとして、本稿ではAstroを何度も例に出しました。Content CollectionsやContent Layer、frontmatterの検証といった流れが、正本Markdownからビルドや多出力へつなげる話と重なりやすいからです。ただしAstroが唯一の正解ではありません。同じ方向性は、静的サイトやドキュメント基盤の別製品にも別の形で見られます。
HugoはMarkdownとfrontmatterを中心にした静的サイト生成の代表例の一つです。DocusaurusはMDXを前面に置き、ドキュメントとUI部品を同一リポジトリで扱いやすいです。Next.jsはAstroやHugoのようなコンテンツ特化基盤そのものではありませんが、MDXや独自のコンテンツ処理を組み合わせて、Markdown中心の公開基盤を構成する選択肢としてよく使われます。採用事例でも触れたエージェント向けのローカルMarkdown docsは、その延長線上の話です。
TinaCMSは静的サイトジェネレータそのものというより、Git上のMarkdownやMDXを編集UIから触るGit-backedヘッドレスCMSの代表例に近いです。Astroなどと組み合わせて、正本をファイルに残しつつ執筆体験を補う、という位置づけになります。
Pagefindはコンテンツ基盤ではなく、ビルド後のHTMLから検索用の索引を作る部品です。本稿の多出力の一つである検索層を、既存の静的サイト出力に後付けしやすい例として覚えておくとよいです。
自分でアプリを組む場合も、これらの製品が担う役割を分解して、エディタ・検証・ビルド・公開・検索のどこを自前にするかを決める、という読み方ができます。
参考リンク
仕様と標準化
実務運用の実例
プロンプト設計の指針
周辺技術と補足根拠
トークナイザと前処理の参考